Quelques Digressions Sous GPL
Julien Vehent on cloud security, risk management and web services engineering.
Latest Posts
-
Are security and reliability fundamentally incompatible?
I have been meaning to write about the Crowdstrike incident, but it seemed important to avoid being caught into the chaotic blame game going around. So let’s get this out of the way first: Yes, Crowdstrike made a terrible technical mistake that they are ultimately responsible for, but No, they probably didn’t have any other ways to go about solving their problems for the products they were trying to build. As someone who has made similar mistakes in the past, I can understand how they happen, and will continue to happen. There are no silver bullets, and any sufficiently complicated system will fail regularly, no matter how much testing, quality assurance, safe coding and so on that you throw at it.
The question that I am interested in exploring here is whether security is fundamentally antagonistic to reliability. Will security solutions that are inherently intrusive inevitably degrade the ability of systems to perform their tasks uninterrupted? And if yes, are there approaches to reduce that impact to a tolerable minimum?
-
Important trends in Cybersecurity
Some observations on how our field is evolving in four distinct areas: security keys, reduction in attack surfaces, regulatory compliance and shifting left,.
Security keys
Perhaps the most impactful trend to security posture is the move away from passwords to security keys, which has eliminated an incredibly large attack surface entirely. We have seen again and again that organizations that fully adopt security keys and webauthn can prevent phishing and password stuffing attacks entirely, but a fair amount of skepticism remained on the maturity of security keys and their practical daily use.
This is changing. Most, if not all, tech companies now require security keys internally and have matured the tooling to manage them. Google Workspace and Microsoft 365 have first class support of security keys, making it easy for administrators to issue and manage the keys.
-
Data Driven Detection Engineering
In which I argue for stronger software engineering skills in cybersecurity, and a focus on data engineering.
My initial foray in the world of detection & response occurred in the mid-2000s, when the field of cybersecurity was still nascent and white hats were figuring out how to industrialize defensive techniques. Back then, the job of a security engineer was to deploy intrusion detection systems across the network and write simple rules that would typically match on IP address or signature hashes.
alert udp $EXTERNAL_NET 53 -> $HOME_NET any ( msg:"DNS SPOOF query response PTR with TTL of 1 min. and no authority"; content:"|85 80 00 01 00 01 00 00 00 00|"; content:"|C0 0C 00 0C 00 01 00 00 00|<|00 0F|"; classtype:bad-unknown; sid:253; rev:4; )an example of snort rule that alerts on suspicious DNS traffic
Security engineers focused primarily on network infrastructure and threat intelligence. Aggregating IOCs, applying rules to well-placed sensors and investigating alerts was an analyst’s primary focus. You’d place tripwires all over the place, and wait for an attacker to trigger an alert.
This seems to have served us well for a long time. We refined it over the years, with more sophisticated alert languages, frameworks like MITRE ATT&CK that helped organize threats, log aggregation systems like Splunk, etc. And judging by the content of most BSides conferences, it is still the go-to approach for a lot of teams out there.
However, my observation over the past five years, first building the threat detection pipeline at Mozilla, then running the Cloud Detection team at Google, is that detection & response has shifted to focus on data driven detection engineering. The future of D&R leverages complex data models using sophisticated pipelines to detect threats in anomalous behaviors. And, as an industry, we’re not ready for it.
-
How not to use Regular Expressions
Earlier this week I shared some strong thoughts on regular expressions with my team. We were discussing how a regex-based deny-list failed and I may have lamented my lack of trust for anything based on regexes, which judging by the eyes rolling probably sounded irritating. So I thought I would share a story from when I started as a junior security engineer back in the mid 2000s. Gathered around the bonfire, grandpa Julien is going to ramble for a minute.
At the time, I was working for a french bank on the security of their web portal. For those who were already in the industry, you most likely remember how everyone was raving about web application firewalls back then. WAFs were the new shiny technology that would solve all our security problems, nevermind how basic they were. They essentially applied perl-compatible regular expressions (PCRE) on URL query parameters. That’s it. They lacked any sort of learning capabilities and had very limited understanding of the web stack. Most didn’t even support TLS. Many increased latency. Some made services more vulnerable just by being on the critical path.
-
Managing Remotely
After five years of managing teams remotely, and a few more as a remote individual contributor, I’ve picked up a few patterns that I thought may be valuable to share. Engineering management is hard. You need to be a good engineer, but also a good manager. New managers typically get into the field by being good engineers for long enough that it is assumed they’ll also be good managers. But people are not computers, and you can’t engineer your way around managing a team efficiently. It’s an entirely new set of skills you have to learn, and one where making mistakes has direct consequences on people’s careers and livelihood.
When managing remote teams, communication is harder, building a culture takes more time, detecting and handling performance issues is more difficult, etc. All the signals you would naturally collect by being surrounded by the people you manage for several hours a day must now be acquired through well established processes. I’d like to describe some of the processes that I found useful.
-
7 years at Mozilla
Seven years ago, on April 29th 2013, I walked into the old Castro Street Mozilla headquarters in Mountain View for my week of onboarding and orientation. Jubilant and full of imposter syndrom, that day marked the start of a whole new era in my professional career.
I’m not going to spend an entire post reminiscing about the good ol’ days (though those days were good indeed). Instead, I thought it might be useful to share a few things that I’ve learned over the last seven years, as I went from senior engineer to senior manager.
-
Beyond The Security Team
This post is the transcript of a keynote I gave to DevSecCon Seattle in September 2019.

Good morning everyone, and thank you for joining us on this second day of DevSecCon. My name is Julien Vehent. I run the Firefox Operations Security team at Mozilla, where I lead a team that secures the backend services and infrastructure of Firefox. I’m also the author of Securing DevOps.
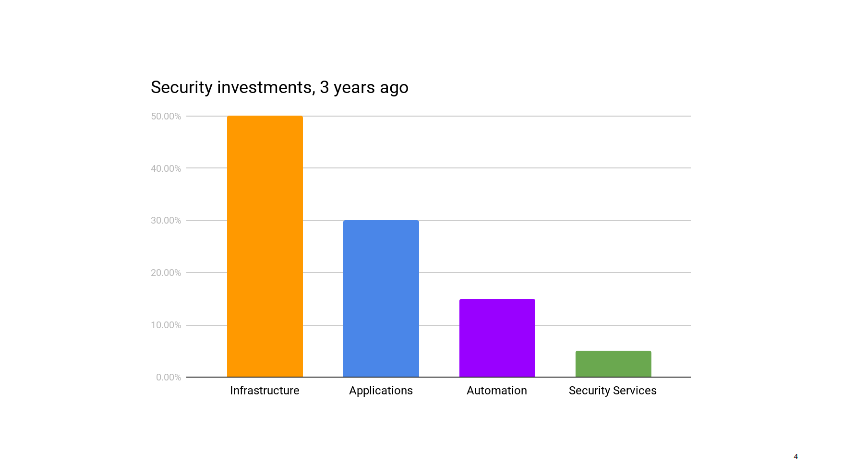
This story starts a few months ago, when I am sitting in our mid-year review with management. We’re reviewing past and future projects, looking at where the dozen or so people in my group spend their time, when my boss notes that my team is under invested in infrastructure security. It’s not a criticism. He just wonders if that’s ok. I have to take a moment to think through the state of our infrastructure. I mentally go through the projects the operations teams have going on, list the security audits and incidents of the past few months.
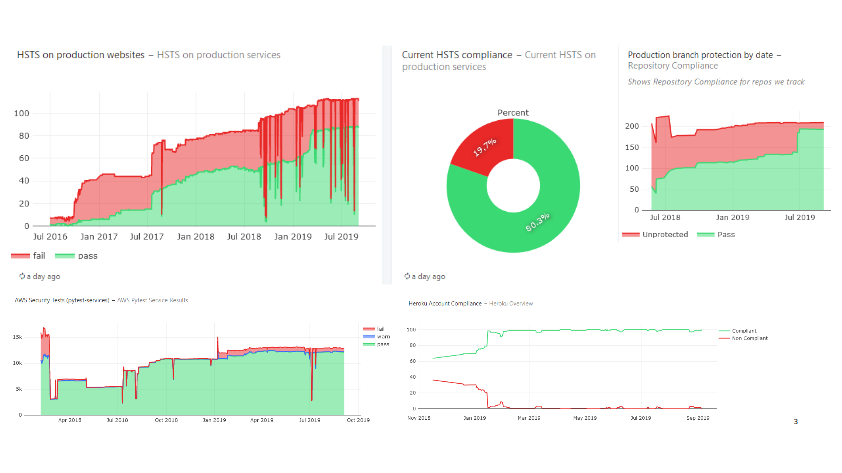
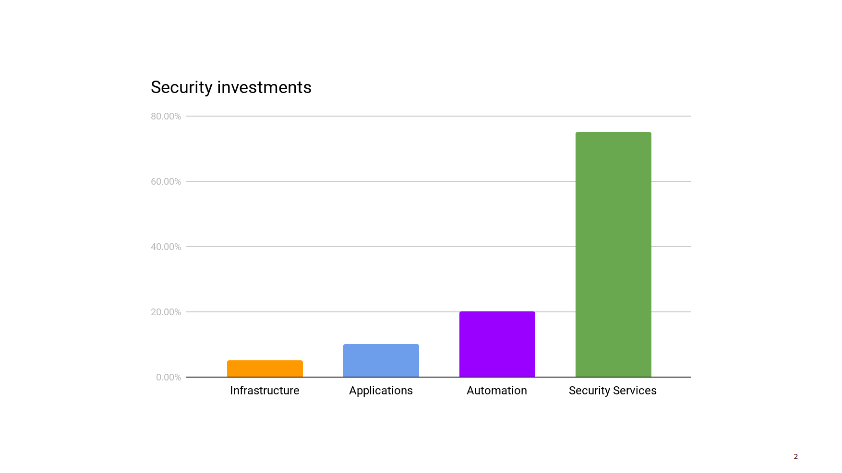
I pull up our security metrics and give the main dashboard a quick glance before answering that, yes, I think reducing our investment in infrastructure security makes sense right now. We can free up those resources to work on other areas that need help.
Infrastructure security is probably where security teams all over the industry spend the majority of their time. It’s certainly where, in the pre-cloud era, they use to spend most of their time.
Up until recently, this was true for my group as well. But after years of working closely with ops on hardening our AWS accounts, improving logging, integrating security testing in deployments, secrets managements, instances updates, and so on, we have reached the point where things are pretty darn good. Instead of implementing new infrastructure security controls, we spend most of our time making sure the controls that exist don’t regress.
-
The cost of micro-services complexity
It has long been recognized by the security industry that complex systems are impossible to secure, and that pushing for simplicity helps increase trust by reducing assumptions and increasing our ability to audit. This is often captured under the acronym KISS, for “keep it stupid simple”, a design principle popularized by the US Navy back in the 60s. For a long time, we thought the enemy were application monoliths that burden our infrastructure with years of unpatched vulnerabilities.
So we split them up. We took them apart. We created micro-services where each function, each logical component, is its own individual service, designed, developed, operated and monitored in complete isolation from the rest of the infrastructure. And we composed them ad vitam æternam. Want to send an email? Call the rest API of micro-service X. Want to run a batch job? Invoke lambda function Y. Want to update a database entry? Post it to A which sends an event to B consumed by C stored in D transformed by E and inserted by F. We all love micro-services architecture. It’s like watching dominoes fall down. When it works, it’s visceral. It’s when it doesn’t that things get interesting. After nearly a decade of operating them, let me share some downsides and caveats encountered in large-scale production environments.
-
Interviewing tips for junior engineers
I was recently asked by the brother of a friend who is about to graduate for tips about working in IT in the US. His situation is not entirely dissimilar to mine, being a foreigner with a permit to work in America. Below is my reply to him, that I hope will be helpful to other young engineers in similar situations.
-
Maybe don't throw away your VPNs just yet...
Over the past few years I’ve followed the rise of the BeyondCorp project, Google’s effort to move away from perimetric network security to identity-based access controls. The core principle of BeyondCorp is to require strong authentication to access resources rather than relying on the source IP a connection originates from. Don’t trust the network, authenticate all accesses, are requirements in a world where your workforce is highly distributed and connects to privileged resources from untrusted networks every day. They are also a defense against office and datacenter networks that are rarely secure enough for the data they have access to. BeyondCorp, and zero trust networks, are good for security.